如朴灵说过,Node对内存泄露十分敏感,一旦线上应用有成千上万的流量,那怕是一个字节的内存泄漏也会造成堆积,垃圾回收过程中将会耗费更多时间进行对象扫描,应用响应缓慢,直到进程内存溢出,应用奔溃。
虽然从很久以前就知道内存问题是不容忽视的,但是日常开发的时候并没有碰到性能上的瓶颈,直到最近做了一个百万PV级的营销项目,由于访问量,并发量都达到了一个量级。一些细小的、平时没注意到的问题被放大,这才映入眼帘,开始注意到了内存问题。殊不知Node对内存的泄露是如此的敏感。
为此,赶紧去补习了一下V8中的内存处理机制。
那么,V8中的内存机制是怎么样的?
#V8的内存机制
#内存的限制
Node中并不像其他后端语言中,对内存的使用没有多少限制。在Node中使用内存,只能使用到系统的一部分内存,64位系统下约为1.4GB,32位系统下约为0.7GB。这归咎于Node使用了本来运行在浏览器的V8引擎。
V8引擎的设计之初只是运行在浏览器中,而在浏览器的一般应用场景下使用起来绰绰有余,足以胜任前端页面中的所有需求。
虽然服务端操作大内存也不是常见的需求,但是万一有这样的需求,还是可以解除限制的。
在启动node程序的时候,可以传递两个参数来调整内存限制的大小。
1 | node --max-nex-space-size=1024 app.js // 单位为KB |
这两条命令分别对应Node内存堆中的「新生代」和「老生代」
#不受内存限制的特例
在Node中,使用Buffer可以读取超过V8内存限制的大文件。原因是Buffer对象不同于其他对象,它不经过V8的内存分配机制。这在于Node并不同于浏览器的应用场景。在浏览器中,JavaScript直接处理字符串即可满足绝大多数的业务需求,而Node则需要处理网络流和文件I/O流,操作字符串远远不能满足传输的性能需求。
#内存的分配
一切JavaScript对象都用堆来存储
当我们在代码中声明变量并赋值时,所使用对象的内存就分配在堆中。如果已申请的对空闲内存不够分配新的对象,讲继续申请堆内存,直到堆的大小超过V8的限制为止。

#V8的垃圾回收机制
#分代式垃圾回收
V8的垃圾回收策略主要基于「分代式垃圾回收机制」,基于这个机制,V8把内存分为「新生代(New Space)」和 「老生代 (Old Space)」。
新生代中的对象为存活时间较短的对象,老生代中的对象为存活时间较长或常驻内存的对象。
前面提及到的--max-old-space-size命令就是设置老生代内存空间的最大值,而--max-new-space-size命令则可以设置新生代内存空间的大小。

#为什么要分成新老两代?
垃圾回收算法有很多种,但是并没有一种是胜任所有的场景,在实际的应用中,需要根据对象的生存周期长短不一,而使用不同的算法,已达到最好的效果。在V8中,按对象的存活时间将内存的垃圾回收进行不同的分代,然后分别对不同的内存施以更高效的算法。
#新生代中的垃圾回收
在新生代中,主要通过Scavenge算法进行垃圾回收。
#Scavenge
在Scavenge算法中,它将堆内存一分为二,每一部分空间称为semispace。在这两个semispace空间中,只有一个处于使用中,另外一个处于闲置状态。处于使用状态的semispace称为From空间,处于闲置状态的semispace称为To空间。当我们分配对象时,先是从From空间中分配。当开始进行垃圾回收时,会检查From空间中存活的对象,这些存活的对象会被复制到To空间中,而非存活的对象占用的空间会被释放。完成复制后,From空间和To空间角色互换。简而言之,在垃圾回收的过程中,就是通过将存活对象在两个semispace空间之间进行复制。

#在新生代中的对象怎样才能到老生代中?
在新生代存活周期长的对象会被移动到老生代中,主要符合两个条件中的一个:
1. 对象是否经历过Scavenge回收。
对象从From空间中复制到To空间时,会检查它的内存地址来判断这个对象是否已经经历过一次Scavenge回收,如果已经经历过了,则将该对象从From空间中复制到老生代空间中。
2. To空间的内存占比超过25%限制。
当对象从From空间复制到To空间时,如果To空间已经使用超过25%,则这个对象直接复制到老生代中。这么做的原因在于这次Scavenge回收完成后,这个To空间会变成From空间,接下来的内存分配将在这个空间中进行。如果占比过高,会影响后续的内存分配。
#老生代中的垃圾回收
对于老生代的对象,由于存活对象占比较大比重,使用Scavenge算法显然不科学。一来复制的对象太多会导致效率问题,二来需要浪费多一倍的空间。所以,V8在老生代中主要采用「Mark-Sweep」算法与「Mark-Compact」算法相结合的方式进行垃圾回收。
#Mark-Sweep
Mark-Sweep是标记清除的意思,分为标记和清除两个阶段。在标记阶段遍历堆中的所有对象,并标记存活的对象,在随后的清除阶段中,只清除标记之外的对象。

但是Mark-Sweep有一个很严重的问题,就是进行一次标记清除回收之后,内存会变得碎片化。如果需要分配一个大对象,这时候就无法完成分配了。这时候就该Mark-Compact出场了。
#Mark-Compact
Mark-Compact是标记整理的意思,是在Mark-Sweep基础上演变而来。Mark-Compact在标记存活对象之后,在整理过程中,将活着的对象往一端移动,移动完成后,直接清理掉边界外的内存。

#Incremental Marking
鉴于Node单线程的特性,V8每次垃圾回收的时候,都需要将应用逻辑暂停下来,待执行完垃圾回收后再恢复应用逻辑,被称为「全停顿」。在分代垃圾回收中,一次小垃圾回收只收集新生代,且存活对象也相对较少,即使全停顿也没有多大的影响。但是在老生代中,存活对象较多,垃圾回收的标记、清理、整理都需要长时间的停顿,这样会严重影响到系统的性能。
所以「增量标记 (Incrememtal Marking)」被提出来。它从标记阶段入手,将原本要一口气停顿完成的动作改为增量标记,拆分为许多小「步进」,每做完一「步进」就让JavaScript应用逻辑执行一小会,垃圾回收与应用逻辑这样交替执行直到标记阶段完成。
#内存泄露排查的工具
#node-heapdump
它允许对V8堆内存抓取快照,用于事后分析。
在程序中引入
1 | var heapdump = require("node-heapdump"); |
之后可以通过向服务器发送SIGUSR2信号,让node-heapdump抓拍一份堆内存的快照:
1 | $ kill -USR2 <pid> |
这份抓拍的快照会默认存放在文件目录下,这是一份大JSON文件,可以通过Chrome的开发者工具打开查看。
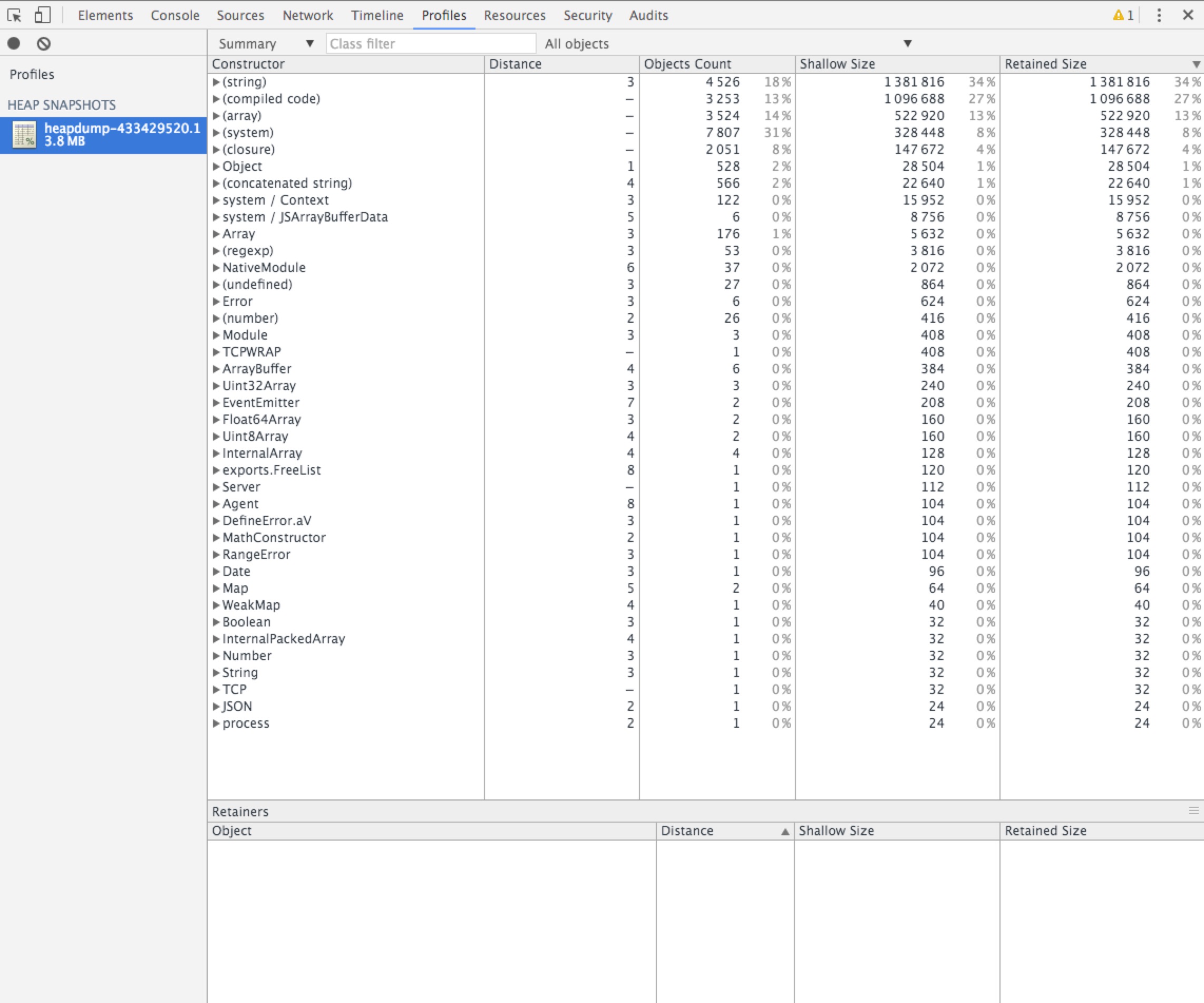
#node-memwatch
需要注意,node-memwatch只是支持到node v0.12.x为止,当使用更高的版本的时候,就会安装不上,这时候可以使用node-watch-next 替代,一摸一样的API。
不同于node-heapdump,它提供了两个事件监听器,用来提供内存泄露的以及垃圾回收的信息:
- stats事件:每次进行全堆回收时,会触发改时间,传递内存的统计信息
- leak事件:经过五次垃圾回收之后,内存仍没有被释放的对象,会触发leak事件,传递相关的信息。
#node-profiler
node-profiler 是 alinode团队出品的一个与node-heapdump类似的抓取内存堆快照的工具,不同的是,node-profiler的实现不一样,使用起来更便捷。附上他们的教程:如何使用Node Profiler
#alinode
alinode官方如似说:
alinode 是阿里云出品的 Node.js 应用服务解决方案,是一套基于社区 Node 改进的运行时环境和服务平台。在社区的基础上我们内建了强大的支持功能,帮助开发者迅速洞见性能细节,快速定位疑难杂症,直探问题根源。

