更好阅读体验:《理解 TCP 和 UDP》— By Gitbook
UDP 和 TCP 的不同
TCP 在传送数据之前必须先建立连接,数据传送结束后要释放连接。
TCP 不提供广播或多播服务,由于 TCP 要提供可靠的、面向连接的运输服务,因此不可避免地增加了许多的开销,如确认、流量控制、计时器以及连接管理等。
而 UDP 在传送数据之前不需要先建立连接。接收方收到 UDP 报文之后,不需要给出任何确认。
虽然 UDP 不提供可靠交付,但在某些情况下 UDP 却是一种最有效的工作方式。
简单来说就是:
UDP:单个数据报,不用建立连接,简单,不可靠,会丢包,会乱序;
TCP:流式,需要建立连接,复杂,可靠 ,有序。
UDP 概述
UDP 全称 User Datagram Protocol, 与 TCP 同是在网络模型中的传输层的协议。
UDP 的主要特点是:
- 无连接的,即发送数据之前不需要建立连接,因此减少了开销和发送数据之前的时延。
- 不保证可靠交付,因此主机不需要为此复杂的连接状态表
- 面向报文的,意思是 UDP 对应用层交下来的报文,既不合并,也不拆分,而是保留这些报文的边界,在添加首部后向下交给 IP 层。
- 没有阻塞控制,因此网络出现的拥塞不会使发送方的发送速率降低。
- 支持一对一、一对多、多对一和多对多的交互通信,也即是提供广播和多播的功能。
- 首部开销小,首部只有 8 个字节,分为四部分。
UDP 的常用场景:
- 名字转换(DNS)
- 文件传送(TFTP)
- 路由选择协议(RIP)
- IP 地址配置(BOOTP,DHTP)
- 网络管理(SNMP)
- 远程文件服务(NFS)
- IP 电话
- 流式多媒体通信
UDP 报文结构
UDP 数据报分为数据字段和首部字段。
首部字段只有 8 个字节,由四个字段组成,每个字段的长度是 2 个字节。

首部各字段意义:
- 源端口:源端口号,在需要对方回信时选用,不需要时可全 0.
- 目的端口:目的端口号,在终点交付报文时必须要使用到。
- 长度:UDP 用户数据报的长度,在只有首部的情况,其最小值是 8 。
- 检验和:检测 UDP 用户数据报在传输中是否有错,有错就丢弃。
UDP 如何进行校验和
伪首部
UDP 数据报首部中检验和的计算方法比较特殊。
在计算检验和时,要在数据报之前增加 12 个字节的伪首部,用来计算校验和。
伪首部并不是数据报真正的首部,是为了计算校验和而临时添加在数据报前面的,在真正传输的时候并不会把伪首部一并发送。
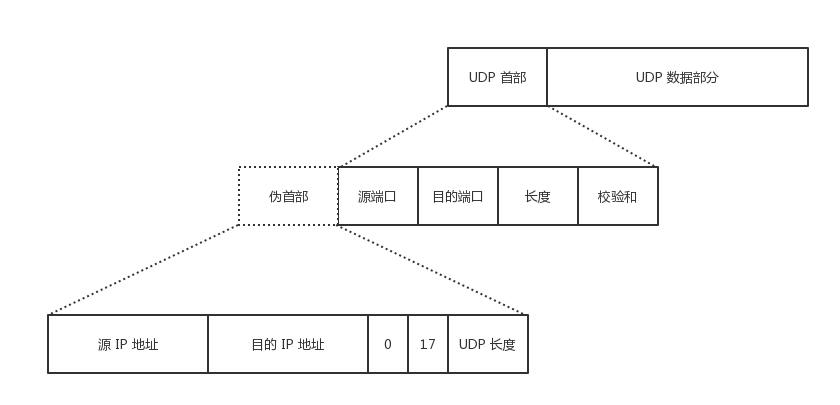
伪首部个字段意义:
- 第一字段,源 IP 地址
- 第二字段,目的 IP 地址
- 第三字段,字段全 0
- 第四字段,IP 首部中的协议字段的值,对于 UDP,此字段值为 17
- 第五字段,UDP 用户数据报的长度
校验和计算方法
校验和的计算中,频繁用到了二进制的反码求和运算,运算规则见下:
二进制反码求和运算
1 | 0 + 0 = 0 |
其中 10 中的 1 加到了下一列去,如果是最高列的 1 + 1 ,那么得到的 10 留下 0 , 1 移到最低列,与最低位再做一次二进制加法即可。
检验和计算过程
- 把首部的检验和字段设置为全 0
- 把伪首部以及数据段看成是许多 16 位的字串接起来。
- 若数据段不是偶数个字节,则填充一个全 0 字节,但是这个字节不发送。
- 通过二进制反码运算,计算出 16 位字的和。
- 让第一行和第二行做二进制反码运算。
- 将第一行和第二行的结果与第三行做二进制反码计算,以此类推。
- 最后运算结果取反,得到校验和。
- 把计算出来的校验和值,填入首部校验和字段。
接收方收到数据报之后,按照同样的方法计算校验和,如果有差错,则丢弃这个数据报。
可以看出校验和,既检查了 UDP 用户数据报的源端口号和目的端口号以及数据报的数据部分,又检查了 IP 数据报的源 IP 地址和目的地址。
一个校验和例子
假设一个 UDP 数据报:
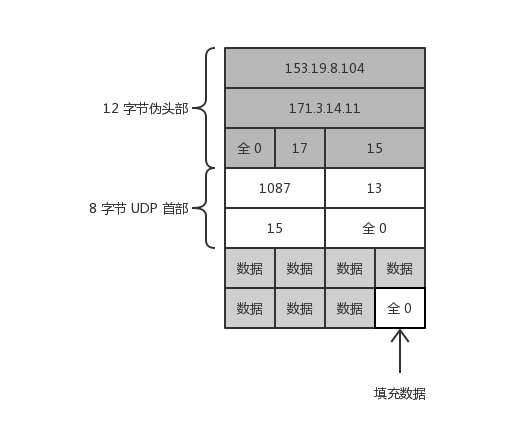
各字段以二进制表示:
1 | 1001 1001 0001 0011 //伪首部源IP地址前16位,值:153.19 |
按照二进制反码运算求和,结果:10010110 11101101
结果求反码得出校验和:01101001 00010010

