一年 AI 实践之后的一些思考
吸了一年高纯度 Token、产出 120w 行代码、近乎丧失「古法编程」技能之后,把过去一段时间的感悟与零散思考重新梳理成文,留作笔记:
- 短短三个月,行业对 Token 的态度从「随便用」变成了「按需用」。 这反映的不是技术退潮,而是一笔从粗放到精细的经济账。唯一被证明的是:需求是真实的,只是目前它还有点贵。
- AI 离真正的「大规模应用」还很远。 想要跨越这道鸿沟,从物理到用户面临三个层面的关卡:物理层(电力)、硬件层(算力)、应用层(工程交付)。而应用层,是我们这种码农唯一能插手的战场。
- AI 要落地为真实的生产力,最大的阻碍不是工程技术,而是组织。 每一次技术突破带来的效率革命,本质上都是对旧组织方式的一次强行「熵减」;在经历阵痛后重塑出新的稳定形态,然后慢慢「熵增」,等待下一次技术革命的到来。
- Prompt / Context / Harness / Loop Engineering 的挨个爆火,除了有王婆卖瓜的成分,其实还藏着一个内因: 一波工具使用者在探索路上撞到的必然共性问题,被有背书的大佬站出来统一了「意识形态」。这让每一个在这条路上蹚水的人都瞬间共鸣——「wc,这正是我想说的」。
#前言
去年下半年,我刚带完一场格式会战——三地六团队三十多人,忙了大半年。会战收官,支援的兄弟们陆续归位,回到各自原来的岗位,格式引擎重新变回几个人维护的常态。这本是仗打完之后的正常收场,但也让我开始想一件事:这么一个跑了好几年、几十万行代码的复杂领域,未来要靠这几个人撑着,那些散落在很多人脑子里的门道,怎么留下来?
那段时间我在琢磨:能不能用 AI,把「领域专家」这件事沉淀下来?于是有了 DocExpert——我把二十万行格式代码当成一个信息论上的「降熵」问题,先做语料工程把它压缩成几百篇结构化文档,再用 RAG 检索喂给模型,配上 Spec 驱动开发(AI-SDD),让 AI 沿着「需求 → 方案 → 拆解 → 实现」往下走。
真正让我心里一震的,是这套管线跑顺之后的一个瞬间:当模型能力本身上来了,再给它套上对的上下文约束、搭好一套像样的架构,它写出来的代码——无论是可读性、命名,还是对格式规范的拿捏——比我自己手写的还要干净。
那是我第一次真切地感到:研发和编码的方式,要被彻底改写了。后来我从 0 立项做的 MindHub(一套围绕大模型的研发支撑系统,把「裸模型」变成可靠的研发生产力),就是从这个判断里长出来的。
这大半年,我自己几乎是泡在 AI Coding 里过来的。一个数字我自己都觉得离谱:这半年我用 vibe coding 写出来的代码,超 120w 行,比我过去十年写的加起来还多。
摆这个数字不是为了显摆用得多深,而是因为:正是用到这个份上,最近半年行业里那些信号,我才格外有体感——它们看着零散,甚至有点互相矛盾,但我隐约觉得,背后有某种共性的问题,还没被说清楚。
这篇就是想把这点东西捋一捋。算不上结论,更像「想到这儿了」的一份个人思考笔记。
#一、风向:不是 AI 不行,是「敞开供应」这种用法太原始
先说最直接的体感:token 的风向,这半年坐了趟过山车。
年初还在「敞开供应」。我自己就在这趟车上——2026.2,我们每人每月能批到 $3000 额度,leader 点头还能加到 $6000,氛围是「你尽管用」。到 6 月,风向收紧,我这份额度被砍到 $1000,而这点钱,我一周就花得干干净净。
不只是我们。微软 2025.12 才把 Claude Code 开放给数千名员工,鼓励大家用 vibe coding 重塑工作流;到 2026.5 就开始收回许可,理由是「烧 token 已经比养员工还贵」。Uber 更夸张,全年的 AI 编程预算,前四个月就烧光了。
半年之内,行业从「随便用」翻到「省着用」。
只看这个表象,很容易觉得:AI 是不是要退潮了?
我的看法正好相反。「烧不起」不是 AI 不行,是我们用它的方式——无论组织怎么管、个人怎么用——都还停在很初期、很粗放的阶段。
为什么这么说?得先把账单拆开,看钱到底花在了哪。
先看单价:根本没涨。 我天天用的前沿模型,Claude Opus 从 4.5 到 4.8 一直钉在 $5/$25(每百万输入/输出 token),几代没动。要说降,是被开源追赶者打下来的:DeepSeek V4-Pro 永久价做到了 $0.435/$0.87,输出价不到 Opus 的零头(约 1/29),而它的编码能力已经摸到 Claude Opus 4.6、世界知识仅次于 Gemini-Pro-3.1——对绝大多数活儿,这个档位早就够用了。所以账单涨,真不赖单价。
真正爆炸的是用量。 Agent、长上下文、一轮套一轮的推理(Reasoning),把单个任务的 token 量撑到了过去的几倍、几十倍——实测推理模型一次回答约是普通模型的 2.5 倍,有些 Agent 产品甚至膨胀到二十倍。哪怕单价原地不动,光是用量这一项,就足以让账单失控。
而用量为什么会这么野?正是因为「敞开供应」——人人不计成本地烧。所以这套供应注定撑不住:它不是被 AI 的失败击穿的,恰恰是被 AI 太好用击穿的。市场规模已经验证,真正的问题,于是从「值不值得用」变成了「怎么才用得起」。风向变了,但方向没错。
#二、三层瓶颈:能下手的,其实只有最上面一层
「怎么才用得起」往深里想一层,其实是同一个问题的另一个问法:AI 要真正大规模用起来,到底有哪些坎得先迈过去?
得先承认,今天还远没到「大规模」。有人把过去 75 年的 AI 采用历程做成了一张可视化的「人海图」,每个点代表约 320 万人——你会直观地看到,真正把 AI 用进日常工作和生产的人,摊到全人类这片海里,仍然只是浮在表面的一层。喊得震天响,落到地上还很薄。
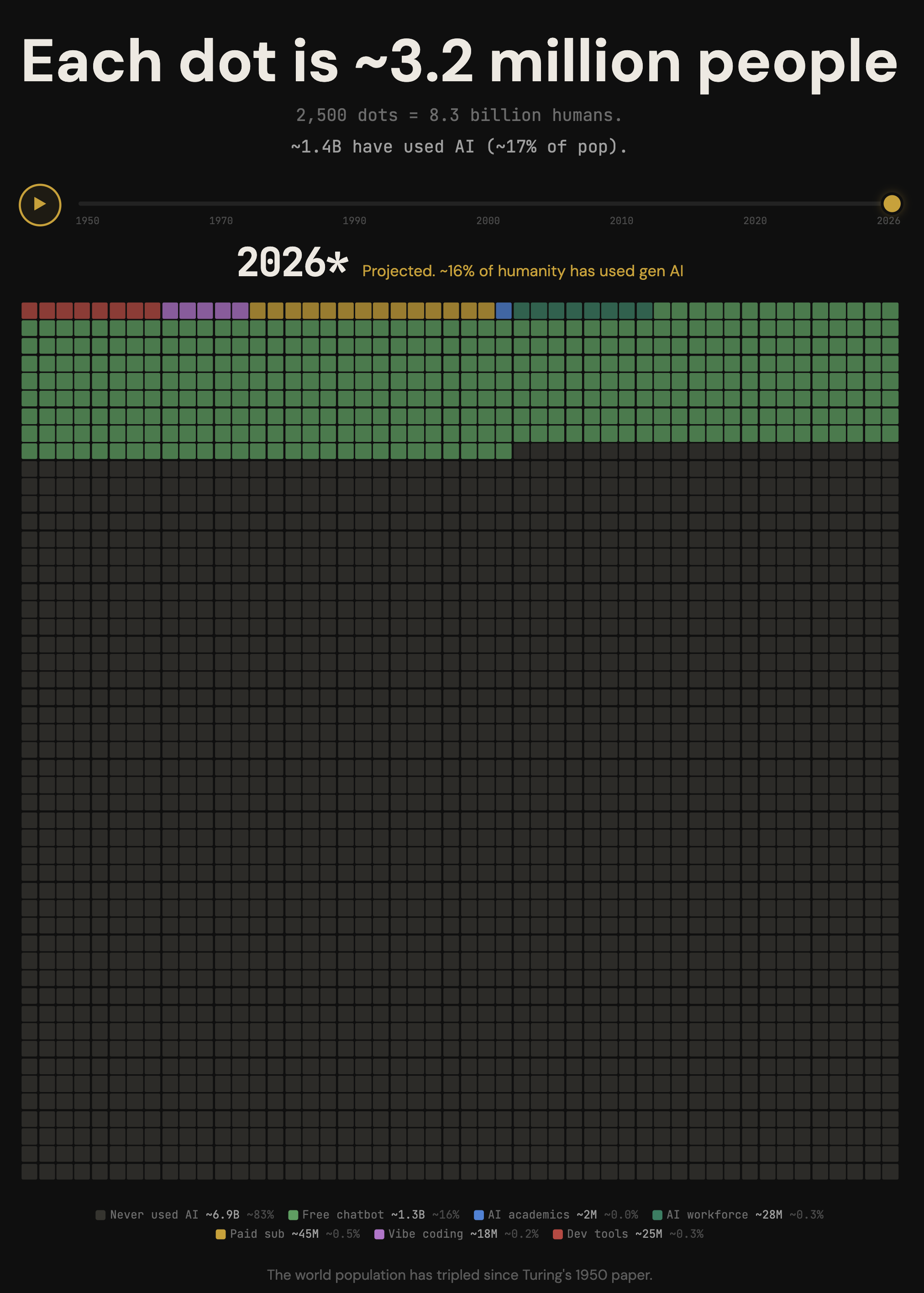
得说清楚:这张图是按西方产品的口径估的,它把 DeepSeek 这类只标了百万级、归进「学术小众」,明显把中国市场漏掉了——光豆包一个 App,2026 年 3 月的月活就有 3.45 亿,DeepSeek 也在亿级,加上千问、元宝、文心,中国的真实渗透率要比图上厚得多。但即便把这块补回去、把整片绿色往上修,结论依然立得住:用过 AI 的是少数,真正靠 AI 吃饭、把它织进生产流程的(图里那一小撮深绿和暖色),更是少数里的少数。这就是今天的「大规模」——离铺满这片海,还差得远。
那么换个问法:假如有一天它真的铺满了这片海,沿途要被解决掉的问题是哪些?我把它们自下而上理成了三层:
物理资源、模型优化、AI 应用交付。

最底下一层,是物理资源。 这一层撞的是自然世界的天花板——算力、能源、数据中心。
这里有个反直觉的地方:现在卡脖子的,已经不是芯片,而是电。微软有上百亿美元的云订单,因为没有足够的电力,迟迟交付不了。美国 2026 年规划的数据中心,相当一部分卡在变压器、电网这些环节上,而电网的建设周期动辄数年。芯片可以加钱排队,电网不行。
业界现在有句话——「AI 的尽头是算力,算力的尽头是电力」。这层约束硬到已经上升成国家级的赌注:美国那边,连马斯克都认真盘算过要把数据中心搬上太空;中国这边,则是把未来的一部分押在了能源上——雅鲁藏布江下游那种级别的水电工程上马,发电增量已是美国的好几倍。
而且中国押电力,我理解不只是「哪怕芯片落后,也要靠廉价电力的总量把算力追回来」这一层追赶的意思。还有一层更长线的算盘:电力本身可以经由算力「出口」。这其实是「西电东送」的升级版——过去是把西部的电沿着特高压送到东部,现在是把廉价电力就地变成算力,再通过海底光缆,把这份「算力」供给到全球。电以光的形式出海,卖的是结果而不是电本身。当「搬上太空」和「把电变成算力卖向世界」都成了正经选项,你就能掂量出这层物理约束有多重——它不是砸钱当天就能解决的。
中间一层,是模型优化。 这一层是模型厂商的战场——同样一份「智能」,怎么做得更便宜、更快、更省。
前面说的单价被一路打下来,就发生在这一层。但这件事,大多数人插不上手,卡在两道坎:
- 硬件准入门槛:训一个有竞争力的模型,光算力投入就是天文数字,是组织级的门票,不是个人能够着的;
- 知识鸿沟:就算身在大厂、坐在岗位上,预训练、推理优化这些活儿,跟我这种做应用的工程师之间,也隔着一条不浅的专业沟。
所以这一层,注定是顶尖 AI 人才和资本的战场。
最上面一层,是AI 应用交付。 这一层做的事,是把底下两层产出的那份通用智能,对接、交付到一个具体、真实的场景里去——喂给它对的知识、搭好它干活的环境,最终把它送到用户手上,变成实实在在的生产力。让「通用智能」变成「能解决我这个问题的智能」。和底下两层不同,这一层不挑准入门槛:它不要天文数字的算力,也不要预训练的专业积累,凭对业务和工程的理解就能下手。
值得点一句:在这一层之上,其实还站着真正的需求方——用户。底下三层全部的努力,最后都是为了把能力递到他手里。所以三层模型严格说应该是「三层瓶颈 + 一个终点」:物理资源、模型优化、AI 应用交付,三级接力,终点是用户。而至于这一层「用什么工程手段把底层能力供给用户」——这一年满天飞的那些新词,正是在回答这个问题。这一点我留到下一节专门讲。
讲到这儿,三层的关系就清楚了。底下两层决定的是「单位智能有多便宜」,最上面这层决定的是「便宜的智能,能不能真的变成生产力」。
而最关键的判断是:底下两层都在快速变好——电力在大建,单价在猛降——可真实世界的生产力,并没有跟着同比例往上走。姚顺雨把这个叫「效用问题」(utility problem):AI 在各种榜单上早就超人了,可真实世界的 GDP 没怎么动。缺口卡在哪?我认为就卡在最上面这一层。
底下两层我够不着。物理资源是国家和巨头的事,模型优化是厂商的事。作为一个做应用的工程师,我唯一能下手的,就是第三层。
而第三层,恰好是我一年前那轮判断的落脚点。
#三、AI 应用交付这一层:方向我们看对了,也看清了新词是怎么造出来的
上下文工程是工程团队的「唯一」战场——我们碰不到模型参数,但可以精心构造 LLM 看到的上下文。
这句话,是我做 MindHub 立项调研时写下的。「上下文工程」是当时手头最顺的那个词——现在回头看,它说的正是AI 应用交付这一层的活儿。当时我顺手扒了一圈行业里的声音,想确认这个判断站不站得住。今天再看,它正好接住了上面三层模型的落点。
要理解为什么是「上下文」这一层最值得下手,得先退远一点看 AI 这七十年。
回看这张时间线,有一条容易被忽略的主线:
最近这一波能力跃迁,靠的不是又一个更聪明的算法,而是把海量知识喂进了一个已经够好的架构。
算法侧,2017 年的 Transformer 之后并没有再出现同量级的突破;真正让 Agent 在 2023 年集中爆发的,是预训练把海量世界知识灌了进去,模型第一次有了在开放世界里干活的「常识」。不是说算法不重要——没有 Transformer 什么都不成;而是说,当架构这一步已经够用,后面拉开差距的,是知识。
这个判断,不是我一个人的臆测。我扒到三篇来自完全不同视角的文章,它们几乎不约而同地指向同一个方向:
- 姚顺雨《The Second Half》,强化学习视角——让 AI 能泛化的不是更好的算法,是预训练注入的海量知识,「知识 > 环境 > 算法」;
- Karpathy 2025 年度回顾,工程类比视角——LLM 是操作系统、上下文窗口是内存,我们的活儿是备好它运行所需的数据和环境;
- OpenAI《Harness Engineering》,一线实践视角——一个三到七人的小团队,五个月用 Codex 写出约一百万行代码、0 行人工手写,工程师的活儿从「写代码」变成「设计一个让 Agent 能写好代码的环境」。
一个搞理论、一个写工程、一个带团队打仗,在不同时间从不同角度出发,最后收敛到同一句话上:决定智能能不能用好的,不是模型本身,是模型周围那套东西。 三个人撞到一起,我去年的判断,方向上没看错。
但顺着这件事,我想多说几句——关于这一年满天飞的那些新词。
这一年,AI 圈的新词冒得特别快:Prompt Engineering、Context Engineering、Harness Engineering,到最近的 Loop Engineering,几乎一个月换一个。很多人说这是炒作、是换皮。
这些词到底是不是换皮,先别急着下结论。把它们摆到一起、扒一扒底下的东西,会看到三件事。
第一件:它们不是换皮,是同一个方向上的形态进化。
把这几个词按出现顺序摆一排,会发现是人在一步步从 AI 身边往后退:
- Prompt Engineering:你握着 AI 的手,一句一句喂;
- Context Engineering:你不光喂指令,还把它该看的料备齐;
- Harness Engineering:你干脆给它搭好整个环境,让它在里面自己跑;
- Loop Engineering:连「驱动它干活」都交出去——你只定义目标和验收,剩下的让一套循环自己去敲。
从「握着手」到「喂对料」,到「搭环境」,再到「连驱动都不亲自做」。每个新词,标记的都是人往后退的一格。所以它不是换皮,是退后的姿势在迭代。
第二件:所谓新概念,很多时候不是新发现,而是给一种集体的共同体验起了个名字。
这点我有亲身体会。我从今年 1 月就开始做 MindHub——围绕大模型搭一整套研发支撑,做的时候它还没名字。直到 2 月 OpenAI 抛出「Harness Engineering」,我才发现这个词正好能命名我过去大半年在做的事。
但它印证的不是「OpenAI 说我对了」,而是一个机制:当一个工具的使用者基数大到一定程度,大家会撞到高度类似的问题,这时谁用一个词概括了这种共同体验,它就瞬间引起共鸣、火起来,再被无数人接着加工、解读,慢慢偏离本意。
Loop Engineering 就是个活例子:一位开发者发条推说「别再往 Agent 里一句句打字了,去设计一个替你打字的循环」,几天冲到几百万阅读;第二天另一位工程师就发博客把它正式命名。一条推,一个晚上,一个新词就立住了。
所以 harness、loop 这类词能在一夜之间爆火,背后其实是两股劲在合力:
一是它确实戳中了——把成千上万人各自零散的同类体验,用一个词统一成了共同的「意识形态」,大家一看「对,我说的就是这个」,瞬间共鸣;
二是热度本身会自我繁殖——词火了,是个人都想蹭一下、接着解读一句,于是越滚越大,也越滚越偏离本意。
第三件:得留个心眼——提出这些词的人,往往就是卖账单的人。
Context Engineering 出自 OpenAI 的创始成员,Harness Engineering 是 OpenAI 提的,Loop Engineering 的提出者现在也在 OpenAI。而这条「人不断往后退、让 Agent 自己多轮跑」的路线,有个不太被点破的副作用:每往后退一格,单任务烧掉的 token 就翻一截——推理模型本就比普通模型多烧一倍多,Agent 自循环更是动辄十几二十倍。越往后退,账单越厚,而收账的恰好是提词的人。
我不是说这些概念是假的,方向是真的,我自己也在这条路上;但概念的提出者和账单的受益者高度重合,作为重度使用者,这一点得始终拎得清。
所以,拨开一个接一个的新词,你会发现很多时候是同一件事在被反复重新命名、再被层层包装上新的期待。看清这点,比追着每个词跑,省心得多。
#四、AI 应用交付真正难的另一半,不在技术,在组织
把AI 应用交付的方向看对、词也认全,是不是把工程做扎实,事情就成了?
真动手做 MindHub 之后越来越确定:这套「知识驱动智能」的判断,技术只是其中一半,另一半在组织——而组织那一半,要难得多。
这事 Databricks 的 CEO Ali Ghodsi 讲得比我透。他在斯坦福和学生聊 AI 价值链时,有个观点我很认同:企业用不起来 AI,主要不是因为模型不够聪明,而是另外两件事。
一件是,AI 缺企业内部那些藏在人脑里的隐性上下文——流程怎么走、潜规则是什么、当年那个决定为什么那么定。这些东西没人写下来。更麻烦的是组织政治:员工担心自己把经验交出去就被替代了,于是不愿意交。
另一件是,大多数企业只是把 AI 塞进了旧流程里,而没有为 AI 重构一套新流程。Ghodsi 拿他们自己做数据连接器举例(这是他在分享里讲的口径):把 AI 塞进老流程只是省了点时间,真正的飞跃是后来把流程整个推倒重做——重构流程带来的提升,远大于「把 AI 塞进老流程」。
我听完特别有共鸣。因为AI 应用交付里最难的那一块,从来不在技术,而在组织。技术上,把知识结构化、做好检索、搭好环境,这些都有章可循。可「人脑里的隐性知识愿不愿意交出来」「流程肯不肯为 AI 推倒重来」——这两件事,没有一行代码能直接解决。
#五、从 MindHub 的落地,看「为什么有人吃到红利、有人还没动」
MindHub 做到现在,我是有成就感的。
它已经接进了不少研发项目,也跑出了几个像样的标杆案例——线上 Bug 的 Oncall 从人工流转变成自动流转,产品经理不写代码也能自己做出可点击的原型。这些是实打实的结果。
它大概长这样——一张脱敏后的全景图,隐去了内部基础设施和具体业务代号,只留结构。不必细看每个格子,扫一眼分层就行:最底下是被封装的外部底座,往上是可复用的内核(记忆、LLM 网关、可观测、知识检索等几根能力支柱),内核之上长出研发租户和孵化的标杆产品,最外面统一接入多种 IDE 宿主;一条主轴 MindFlow 把「需求 → AI 实现 → 自动验证 → 交付」串起来。说白了,就是把 OpenAI 那篇 Harness Engineering 讲的事,落成一套自己团队能用的工程底座。

(这是脱敏后的示意图,隐去了内部系统、具体业务与量化数据,只保留分层结构与命名。)
它没有在整个部门一夜之间铺开——这一点,从一开始就在预期之内。一套新的研发范式,本就不可能被所有人同时接受。
真正值得拆开看的是另一个现象:同样一套东西,为什么有的人用得风生水起,有的人却迟迟不动?
拆开之后我发现,这事跟 Ghodsi 讲的,根本是同一件事的两面——分水岭不在工具,在「人和流程动没动」:
- 跑得快、愿意动的那批人和产品,先吃到了红利。 他们愿意把领域知识喂进去,也愿意为 AI 改流程,于是 MindHub 在他们手里转得飞快。
- 跑得慢、还没动的那批,恰好印证了 Ghodsi 说的瓶颈。 不是工具不好用,是隐性知识还在脑子里没交出来,是旧流程还没为 AI 让位。
这种「先动的人先受益」的分化,其实并不新鲜。最典型的是电力替代蒸汽动力的头几十年:真正把效率提上去的,是那些懂得围绕电机重新设计车间布局的工厂;而多数只是把电机一换、产线照旧的,提升寥寥。
工具到位,从来不等于效率到位。中间总隔着一段「先改的人和后改的人拉开差距」的日子。这是生产力跃迁绕不过的阵痛期,AI 这一次,大概也逃不开。
而且这一次被重排的,恐怕不只是车间布局,还有分工本身。今天科技公司里「老板、产品、前端、后端、测试、运维」这种界限分明的角色划分,我猜会一点点模糊、甚至被打散,朝某种新结构演进——一个人借 AI 同时干完过去几个角色的活,不再是稀奇事。
往大了看,每一次技术突破带来的效率革命,几乎都在对旧的组织方式做一轮「熵减」:降本、增效、扁平化,把冗余的层级和分工压掉。然后在新结构稳定下来之后,组织又会慢慢「熵增」、重新长出新的层级和山头,直到下一次技术革命来临,再被推倒重排一次。AI 这一轮熵减,现在才刚开了个头。
所以问题就摆在这儿了:怎么让红利从「少数跑得快的人」,扩散到更多人?
我现在的判断是——光靠自下而上的自发采用,不够。
自发采用有个天然的天花板:它只会发生在那些本来就主动、本来就跑得快的人身上。这批人吃饱了,剩下的大多数,不会因为「有个好工具」就自动跟上,因为挡住他们的不是工具,是流程和习惯。
要让 AI 真正铺开,光靠自下而上不够,还得有一股自上而下的力量下场——但不是发个文件、一刀切推行的那种自上而下。它更像「农村包围城市」:让真正懂 AI 的人——比如组织里做 harness 的团队——主动走到一线业务里去,挑一个真实需求,亲手用 AI 从头跑通,在这个过程里,顺带把那条卡了很久的旧流程重做一遍。先在一个个具体的「点」上做出样板,再让这些样板去包围、松动那些还没动的「面」。
样板一旦立住、流程一旦被重做,就会反过来「逼」那些还在观望、不愿动的人改变。而很多时候,人就是这样——被推着用上了,真正尝到甜头,才会回过头说一句「真香」。
这不是我已经验证过的结论,是我现在押的方向。对不对,得让时间来说。
而押下这个方向,对我个人也意味着一次职业的转型。我做了很多年前端,但这一年,我在有意地把能力的重心从「前端工程师」往 AI 上挪——学模型、学 Agent、学怎么把 AI 变成可靠的生产力。我有个预感:一个叫「AI 应用工程师」的岗位,正在或者已经诞生了。与其等这个岗位来定义我,不如自己先走过去。
#最后
写到这儿,前面那些乱糟糟的信号,在我心里大致归位了。
token 从敞开到收紧,不是退潮,是用法在回归理性。概念一个月换一个,也不全是炒作,更多是人在一步步退到 AI 身后——只是别忘了,提词的人往往也在卖账单。而企业迟迟用不起来,问题真不在模型聪不聪明,在组织和流程肯不肯为它让路。
说到底是同一件事的几个侧面——AI 的瓶颈,早就从「模型够不够聪明」,挪到了「我们这些用它的人和组织,跟不跟得上」。
至于更远的地方,价值大概会像每一次技术浪潮那样,慢慢从底层流向应用层。回想 PC 互联网和移动互联网这二十年,真正赚到钱、长成巨头的,是淘宝、微信、美团、抖音这些应用,而不是底下的 TCP/IP、不是默默铺光纤的管道。这一次 AI,我猜也差不多——底座决定下限,但红利的大头,终究落在离用户最近的那一层。
但再往后,AI 真的大规模用起来之后,社会会变成什么样——说实话,我还想象不出来。
所以这篇真的只是「想到这儿」的一份笔记,不是什么结论。先记下来,继续走着看。
#参考
- 极客公园,《微软按下 vibe coding 暂停键:烧 token 已经比员工贵了》 — https://www.geekpark.net/news/364822
- 量子位,《DeepSeek V4 把同等智能价格打到几分钱》 — https://www.qbitai.com/2026/04/407850.html
- Epoch AI,《How much energy does ChatGPT use?》 — https://epochai.substack.com/p/how-much-energy-does-chatgpt-use
- 36氪 / 硅基观察Pro,《马斯克:把 AI 算力搬上太空》 — https://36kr.com/p/3671736378581892
- 21 世纪经济报道,《电力决胜 AI 时代,中国发用电能力领跑全球》 — https://m.21jingji.com/article/20260204/herald/2261a8f726b2cd2e93fe141e852631af.html
- 姚顺雨,《The Second Half》 — https://ysymyth.github.io/The-Second-Half/
- Andrej Karpathy,《Year in Review 2025》 — https://karpathy.bearblog.dev/year-in-review-2025/
- OpenAI,《Harness Engineering》 — https://openai.com/zh-Hans-CN/index/harness-engineering/
- Addy Osmani,《Loop Engineering》 — https://addyosmani.com/blog/loop-engineering/
- Ali Ghodsi(Databricks CEO)斯坦福 AI 价值链对谈(整理) — https://x.com/BoringBiz_/status/2053550601636888978

